Egocentric Vision for Human Movement Prediction
Vision: As wearable sensors start to approach maturity thereby enabling larger datasets of human interaction in natural environments; as computer vision enters the next phase from solving static recognition problems to dynamic video understanding and interaction problems; and as developments motivated by "the metaverse" drive down the cost of wearable tech, a space is opening up for assistive devices to leapfrog to the next level. Our work serves as an initial proof of concept for this vision.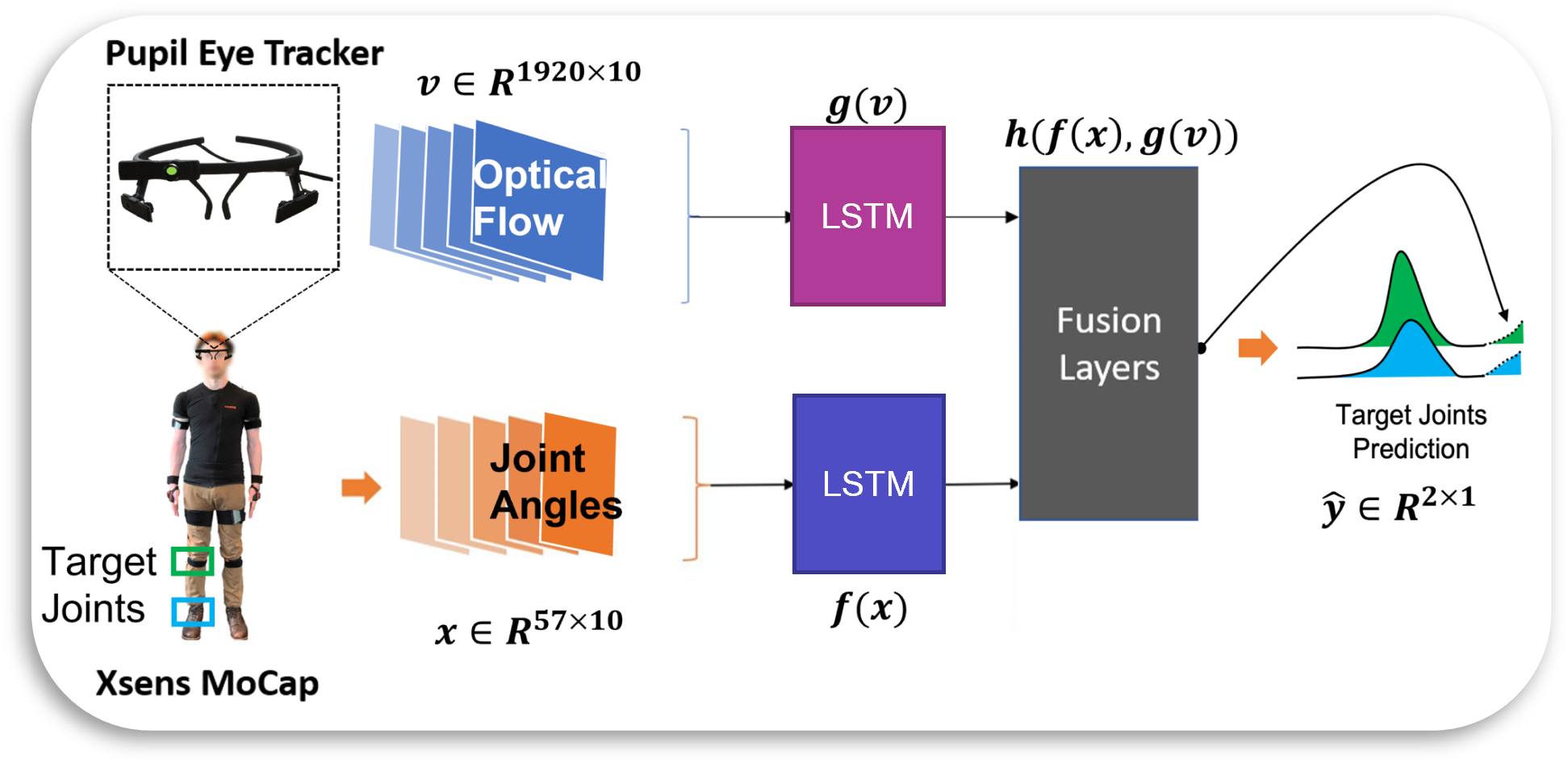
In Coordinated Movement, we presented a novel data-driven approach to controlling assistive devices. The approach relies on predicting knee and ankle joint angles from the rest of the body, and using them as reference for the assistive devices to follow.
Here we fuse motion capture data with egocentric videos to improve the joint angle prediction performance in complex uncontrolled environment like public classrooms, atrium and stairwells. The optical flow features are generated from the raw images, by PWC-net trained on the synthetic MPI-Sintel dataset, and processed by a LSTM before being fused with the joint kinematics stream.
In the following video, we can see that the information about the future movements of the subject is available in their visual field, both in terms of what lies ahead of them e.g. stairs or chairs, as well as how they move their head and eyes for path-planning. Thus, vision acts as a "window into the future".
Egocentric vision improves the prediction of lower limb joint angles
The following videos and the corresponding figures show example maneuvers and the improvement achieved over just kinematics inputs (red line), by fusing kinematics and vision inputs (green line).
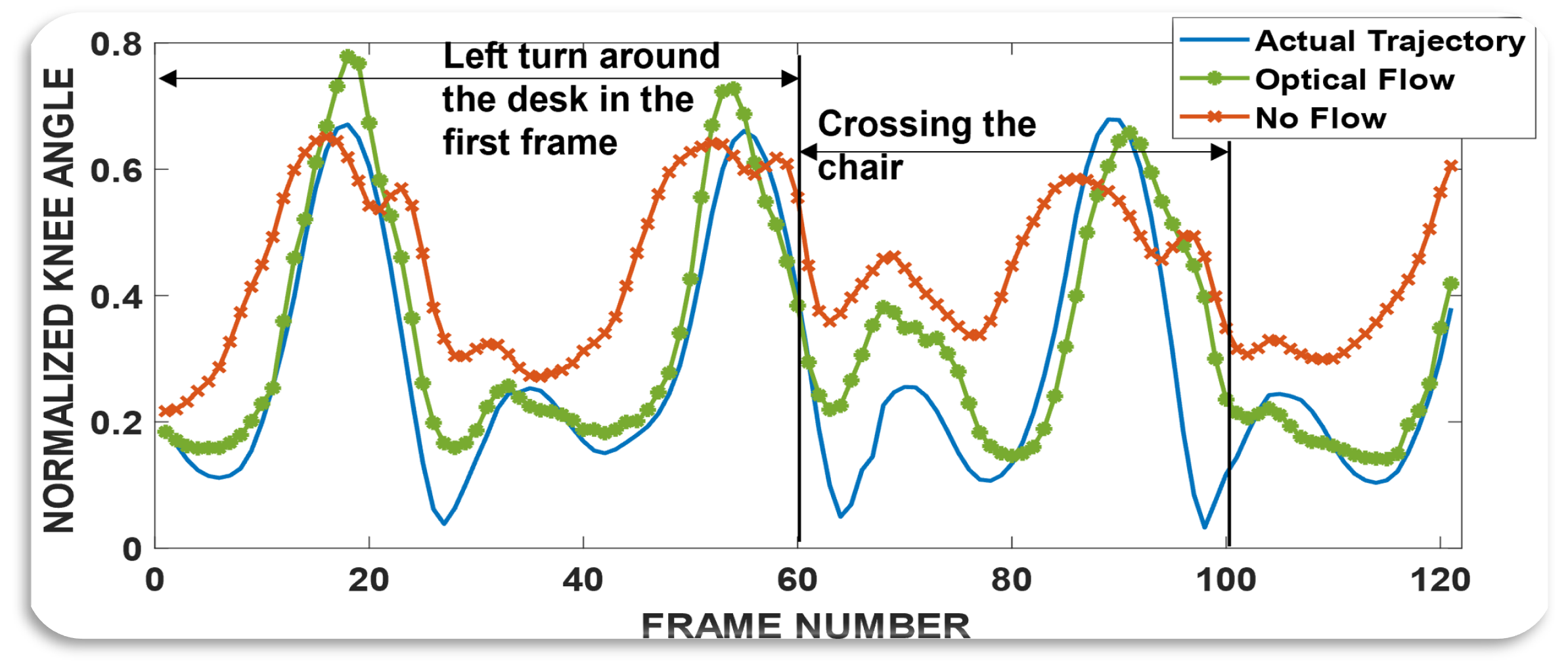
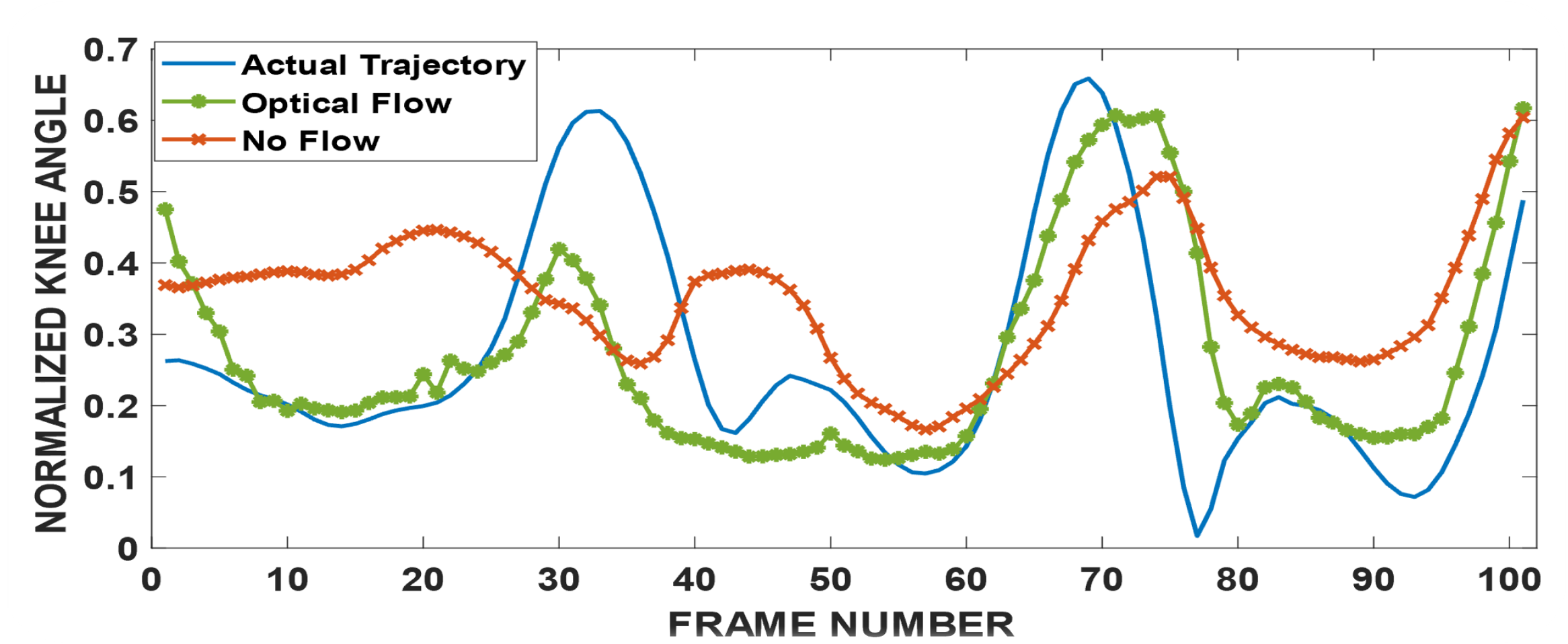
The benefits of egocentric vision can be amplified with more data
In the figure below, we compared performance improvements due to vision with increase in the amount of data per subject (left) and increase in the number of subjects (right). We see that inclusion of vision shows better improvement than no vision condition, for both the cases. We also see that rate of improvement for vision reduces slowly compared to the no vision condition. Indicating that with more data better performance could be achieved.
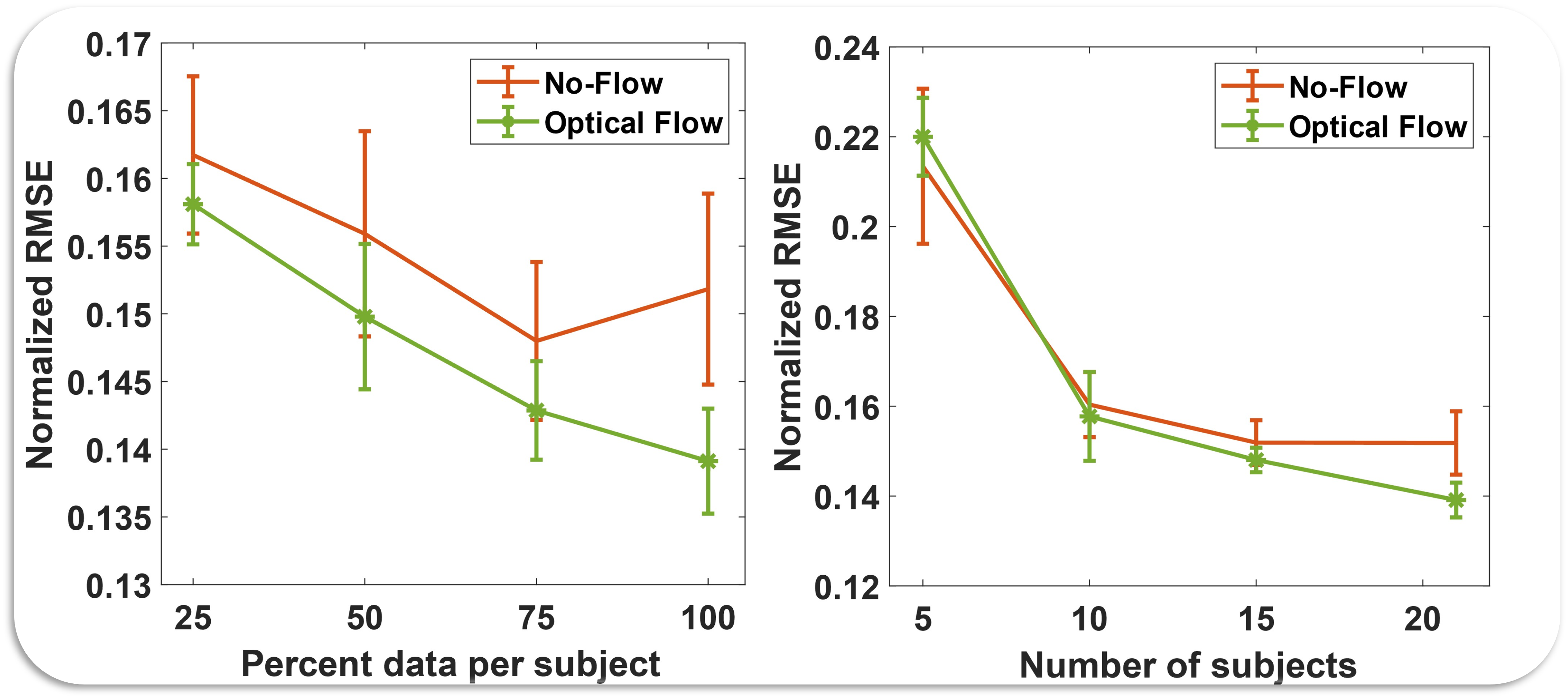
NOTE: The optical flow features were generated by a network trained on synthetic data, and that network weights are never updated using our images. Thus, there is potential for further improvement by either backpropagating and updating the weights of the optical flow feature extractor (PWC-net) or by pretraining the feature extractor on a section of our vision data. That is beyond the scope of current work.
We collected 12 hours of full body motion capture and egocentric vision data (over 1 million vision frames), from 23 participants. The data will be available on figshare. The code is available on github. The paper is available on IEEE TNSRE